
Not long ago, I posted a small article called “Why is (there) Kubernetes?”. Its content inspired me to create a short presentation trying to answer the questions “What and Why is there Kubernetes?”. See below the recording and its summary after.
What and Why is there Kubernetes?
What?

- source: https://kubernetes.io/
- In order to better understand, let’s continue with a story of “Why?”
Why?
- Short and simplified interpretation of the history
- Not so long ago…
- It was pretty common to have these large monolithic applications
- Maybe just a Java jar that contained the service and its dependencies?
- And this would be deployed by SSH-ing into the Production virtual machine?
- Creating environments would be a lot of manual work
- True, configuration management and infra-as-code tools appeared

- But the problem was not completely solved
- Local development environments would be quite different from stage and production environments
- …if there even were so many environments
- Remember this?

- “And then Docker was created”
- And then Docker was created

- Now you can ship your dev machine

- But… “Sometime in this timeline, microservices became a thing”
- Sometime in this timeline, microservices became a thing

- source: https://microservices.io/
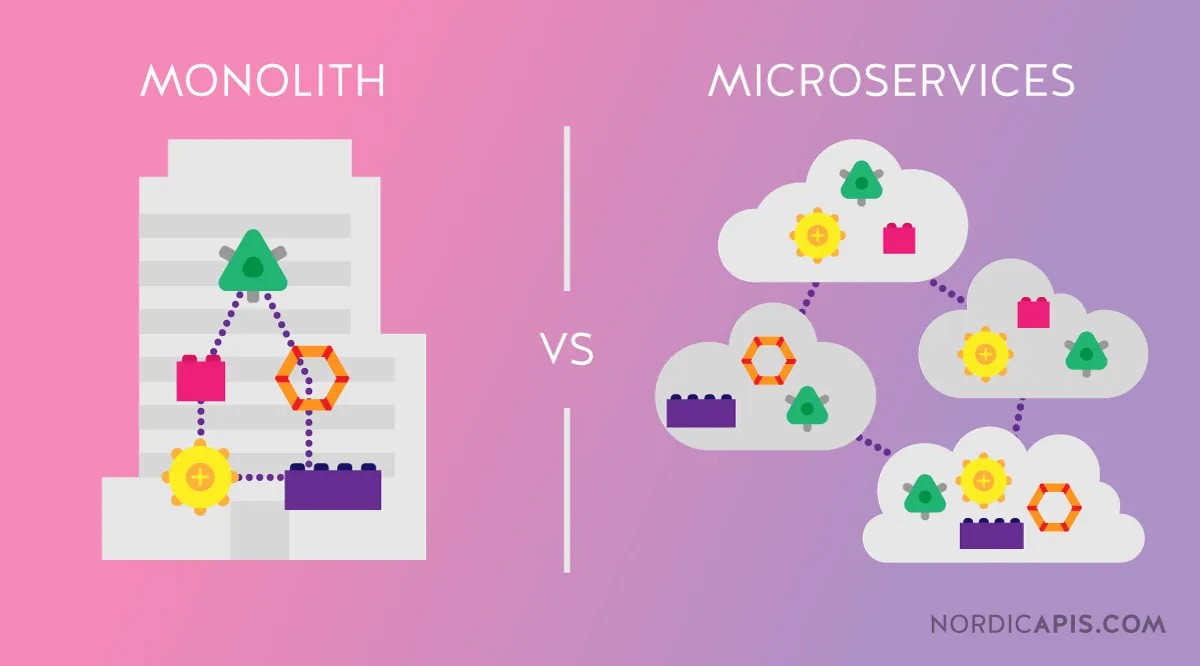
- So everyone started splitting their monoliths
- Which meant that instead of having to deploy 1 or 2 Docker container you had to deploy TENS of them

- source juggler: http://www.circusberzercus.co.uk/elfic-the-juggler/
- source docker logo: https://www.subpng.com/png-6rhdhk/download.html
- What about scaling them differently?
- Enter Kubernetes!

- So what is Kubernetes? “What? continued”

 source:
source: 

What? continued
- Let’s have a look at this again
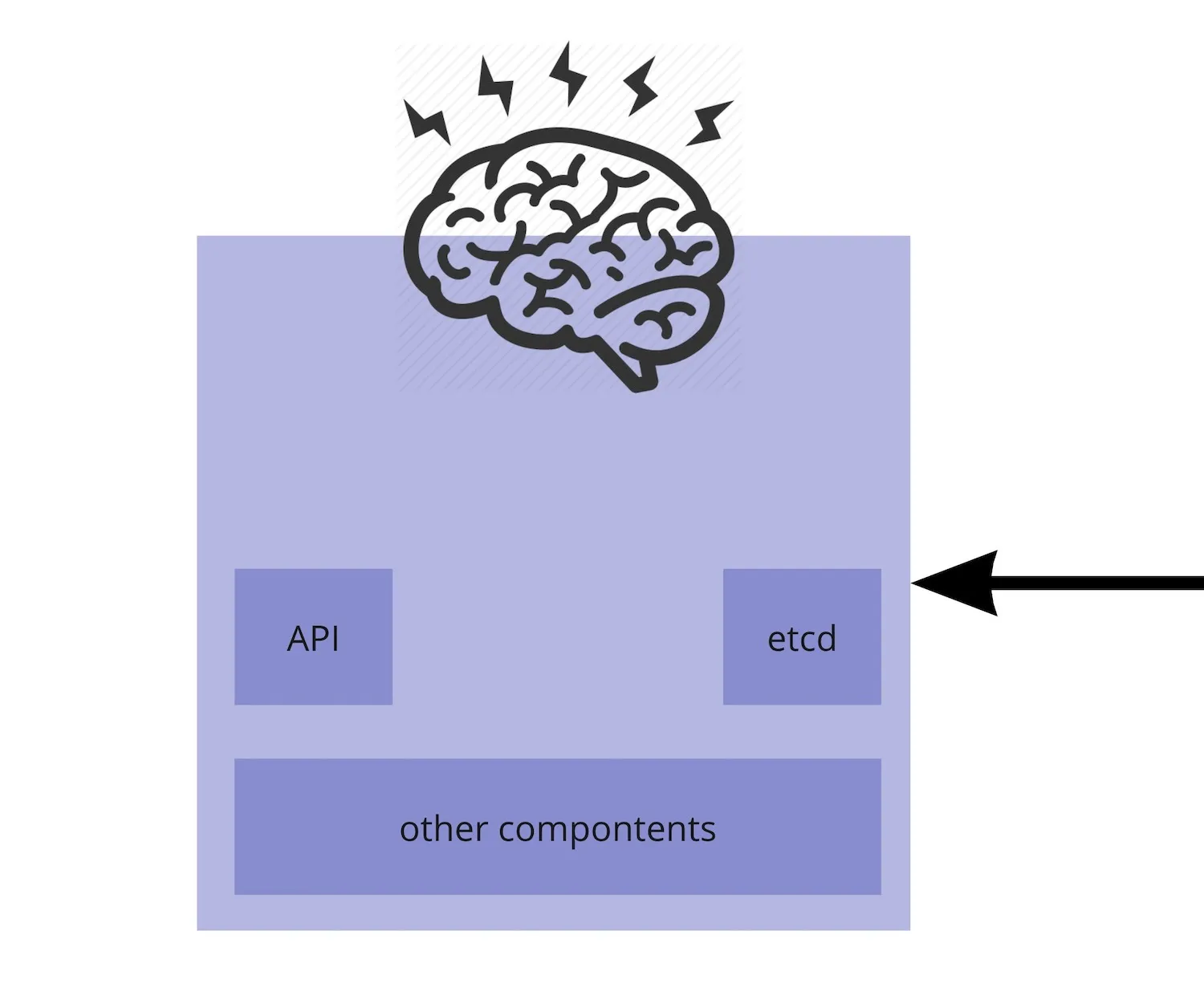
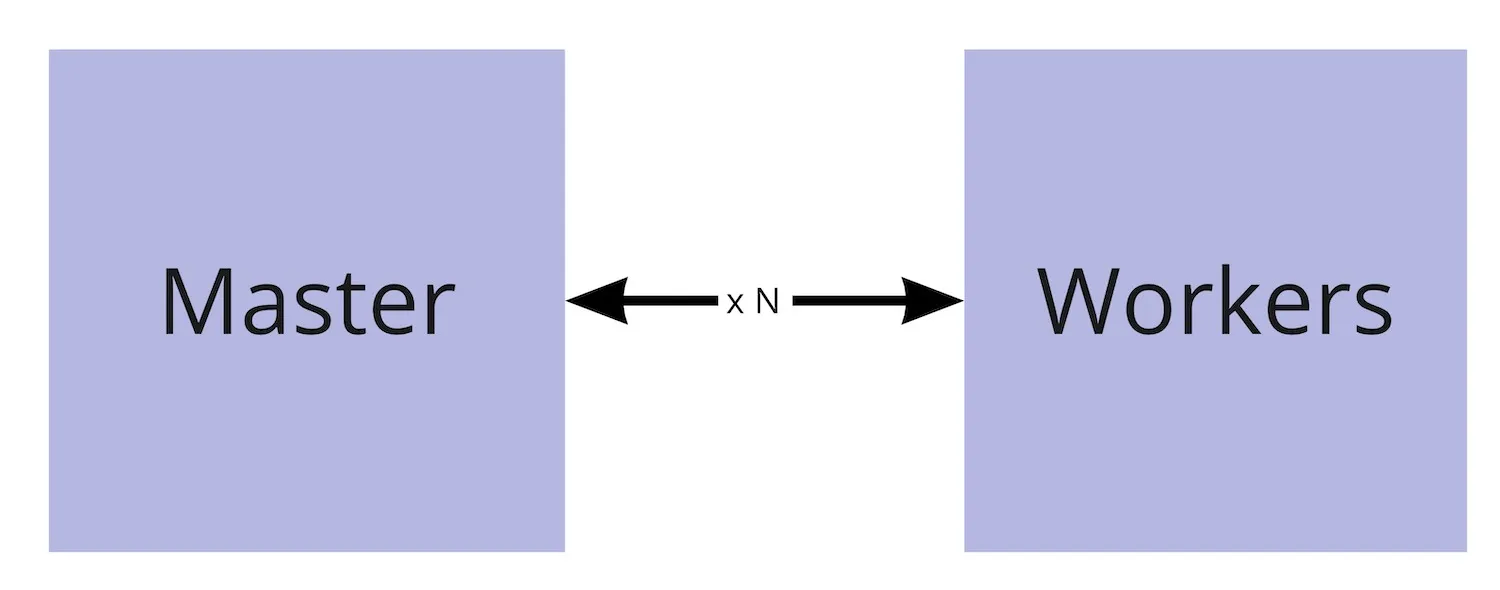
- I see Kubernetes being composed of logical 2 components
- Master and Workers
- An imperfect analogy
- Master <-> our brain
- Workers <-> the other parts of our body that our brain controls
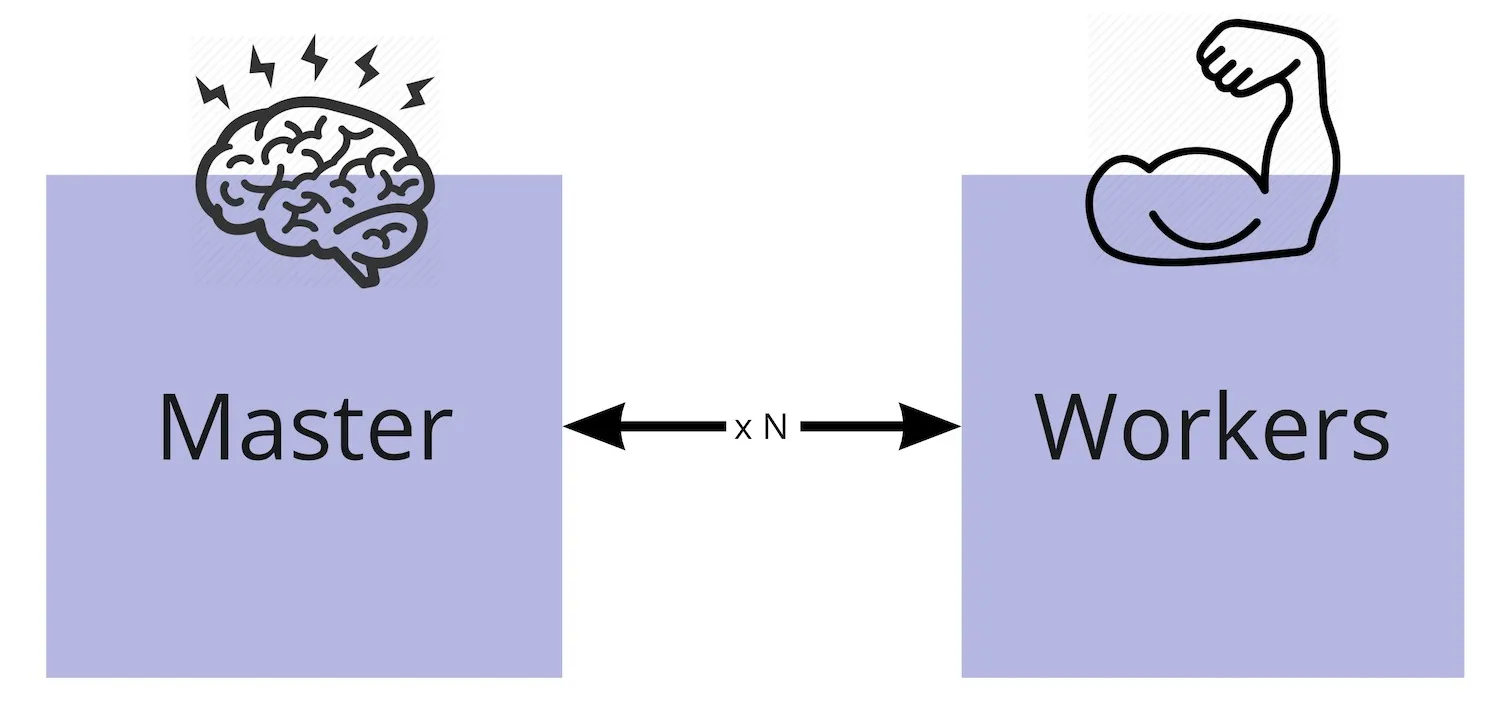
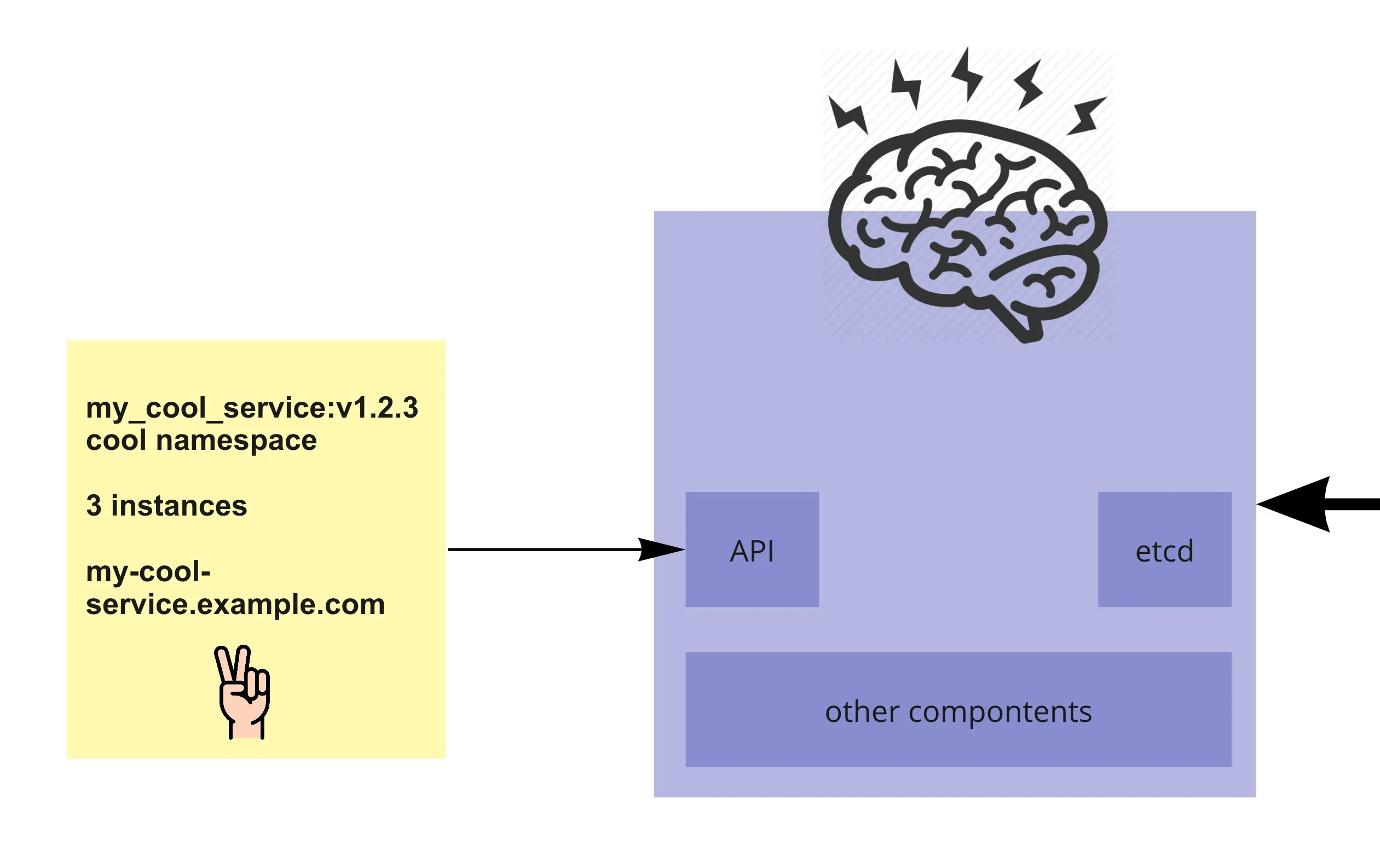
- The Master includes (besides other components)
- The API server - most of the communication with the cluster and between its components happens through the API
- etcd - a key value database where the state of the cluster is kept (the cluster “memory”)
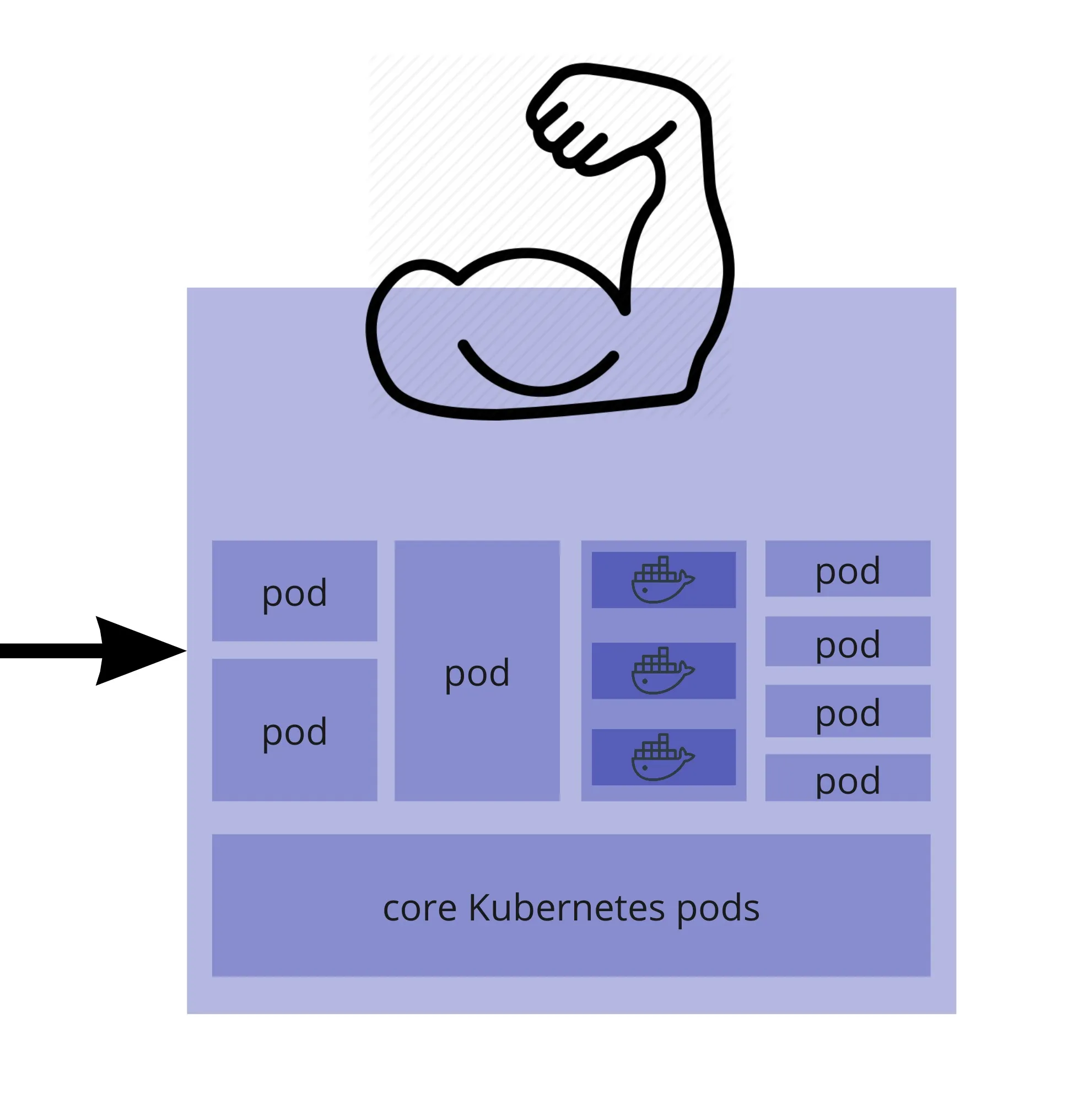
- Zooming on a Worker (which is basically a VM) - a cluster can have several workers
- There are several Kubernetes processes
- And a number of pods which each contain 1 or more Docker containers
- The services deployed on the cluster run in these containers
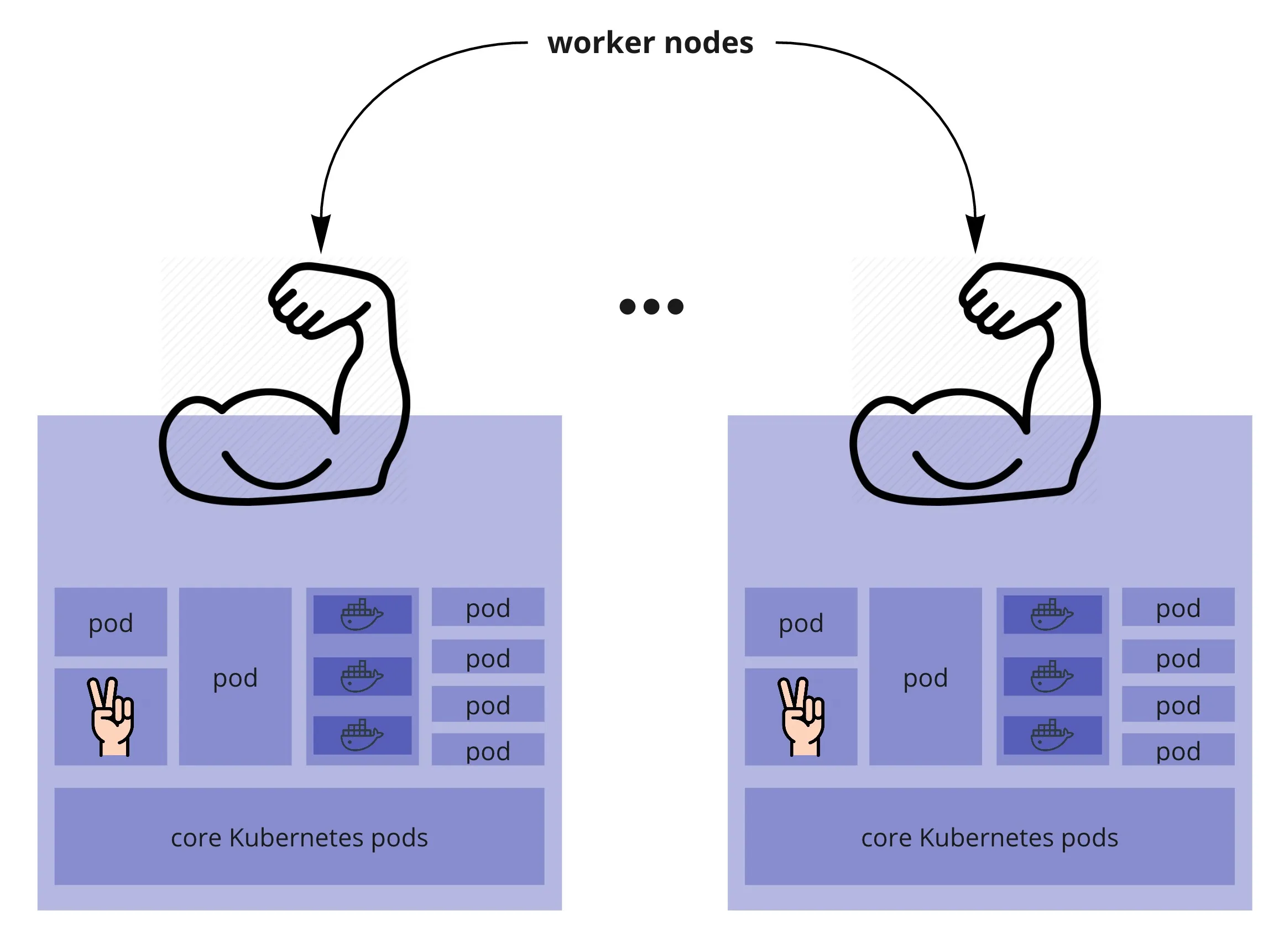
- Master and Workers
- When we deploy a service, we tell Kubernetes what is the end state we want (how many instances of the service, how should it be exposed outside the cluster etc.)
- And if it has the resources available, it will make it happen
- Kubernetes will try to spread the instances (pods) along its worker nodes
- Or if it doesn’t have enough nodes with available resources, it might put all instances (pods) on the same node
- One more thing… namespaces
- Pods, services, many Kubernetes resources are organised in namespaces across nodes
- Namespaces provide isolation between the resources in the cluster
- You can assign roles to users and give them access to do specific actions on specific namespaces

- In reality, pods might look more like this when it comes to namespace distribution across nodes
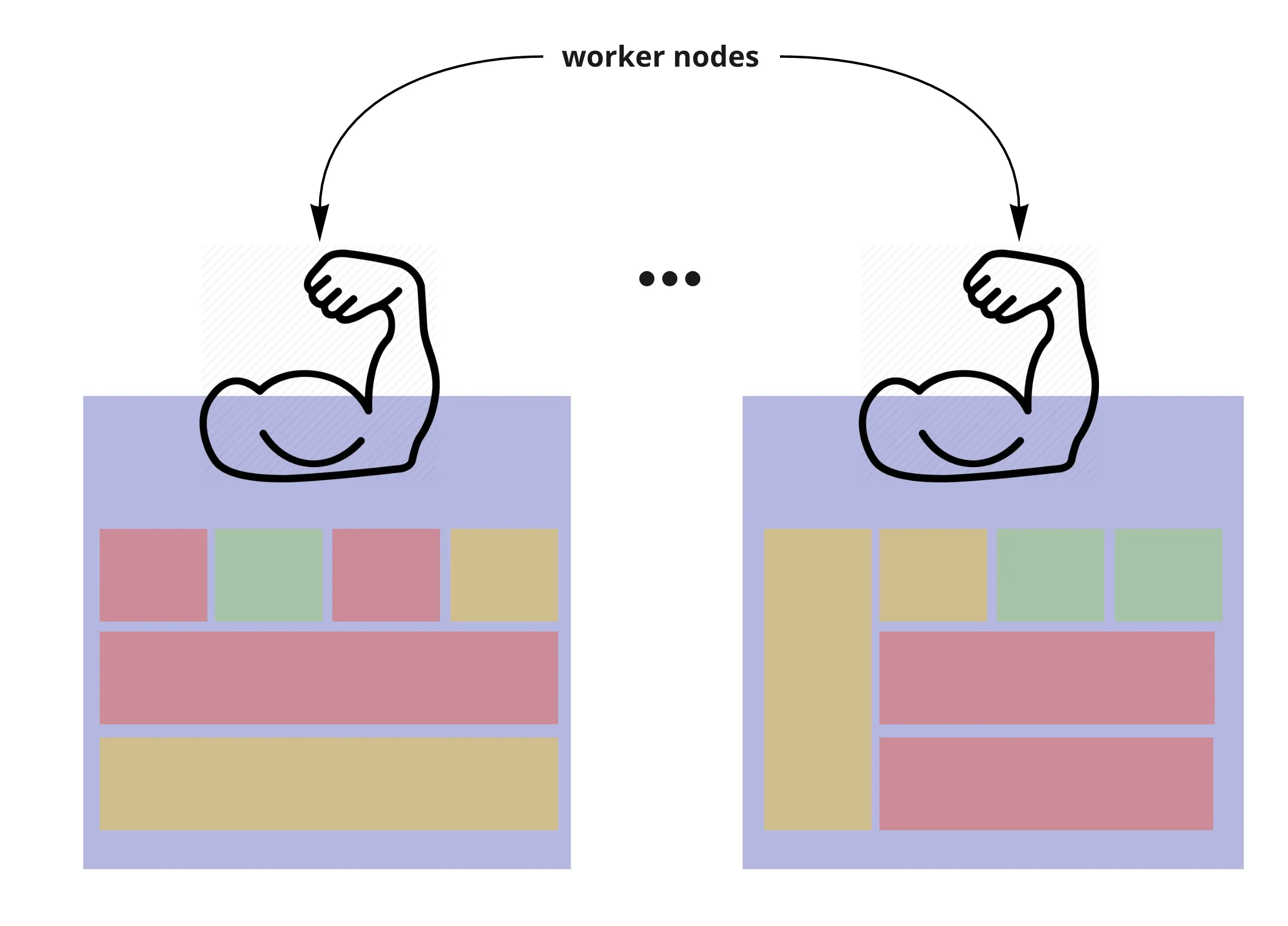
- (rectangles are pods of different sizes, colours represent the namespace they are part of)

{kind=link}